
Introducing GPTadvisor's AI evaluator: Deploy AI solutions with confidence
We have implemented and AI evaluator that measures the quality of our agents without any human intervention
In wealth management, precision isn’t optional, it's expected. That’s why many institutions adopting GPTadvisor dedicate internal teams to verify whether each AI-generated response is accurate, well-structured, and aligned with compliance and internal guidelines.
Before: Manual Checks, Limited Coverage
For many financial institutions, deploying AI comes with a hidden cost: human reviewers.
After going live into production, the entity must devote a team whom main tasks are:
Manually verifying the accuracy of data in our answers (such as returns or fees)
Checking that the source of information for each response are correct and well interpreted
Reviewing tone and format to ensure the response follows internal protocol.
This process is time-consuming and limited in scope. Most institutions can only afford to review a small fraction of conversations. Some of our clients are currently producing thousands of conversation per month, which are impossible to track.
Another challenge: Very little user feedback.
Despite the importance of accuracy, the reality is that users rarely spend the time to flag issues and provide feedback. In fact, our findings show that less than 1% of conversations receive any type of feedback. This means most possible improvements go undetected, not because they aren’t important, but because they simply aren’t reported.

The solution: Fully automated QA evaluation
We have implemented an automatic AI oversight that monitors all conversations of our agents delivering detailed feedback metrics on the quality of responses. With this new module, institutions no longer need to allocate human capital to validate answers. Instead they receive the complete evaluation report in their inbox.
How does it work?
We have trained a reasoning model that supervises:
The user’s original question
GPTadvisor’s full response, including the whole set of data sources used to compose the answer
GPTadvisor role instructions, guidelines and authorized behaviours.
Then, it runs a multi-layered evaluation:
Answer validation: The evaluator verifies that the agent is efectively responding to the user query.
Guardrail alignment: The evaluator verifies the answer falls within the authorized scope of the agent and checks that it does not break any guardrails.
Fact-checking: Validates that all numerical and factual data are accurate and derived from the correct, up-to-date sources.
Benchmarking: Answers can be benchmarked against “reference answers” to ensure best practices and measure deviations.
Variation testing: The evaluator can even generate slight variations of the same question to assess the system’s repeatability and robustness.
MiFID guard: Advisory entities can configure the AI evaluator to flag conversations that may pose compliance risks under MiFID II or violate the entity’s internal advisory conduct policies
The results are compiled into clear, exportable reports with detailed metrics, categorized feedback, and pinpointed areas for improvement. Early adopter institutions receive them in Excel or PDF format, aligned with their preferred review cycles. They have already established weekly or monthly evaluations to continuously monitor and refine AI performance.
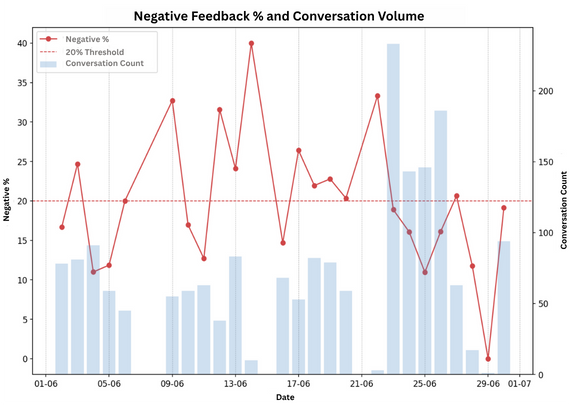
Beta testers gain complete visibility into AI performance without adding operational overhead. What once required hours of manual review and selective sampling is now continuous, automated, and built to scale. The evaluator conducts holistic, 360-degree checks across all conversations
Launch Date
The AI Evaluator module is fully embedded within GPTadvisor and requires no additional setup. Starting August 1st, all our partners will have access to this powerful, time-saving capability, designed to enhance quality assurance from day one.